
Search Engine Optimization (SEO) is an essential ways to boost your website’s visibility and attract more organic traffic. However, it’s a complex strategy that relies on understanding algorithms and leveraging a wide variety of ranking factors. If you’re looking to become an SEO expert, you’ll need to understand search engine indexing.
In this post, we’ll explain how search engines index websites and how you can boost your rankings. We’ll also answer some frequently asked questions about this SEO concept. Let’s get started!
What Is Search Engine Indexing?
Search engine indexing refers to the process where a search engine (such as Google) organizes and stores online content in a central database (its index). The search engine can then analyze and understand the content, and serve it to readers in ranked lists on its Search Engine Results Pages (SERPs).
Before indexing a website, a search engine uses “crawlers” to investigate links and content. Then, the search engine takes the crawled content and organizes it in its database:
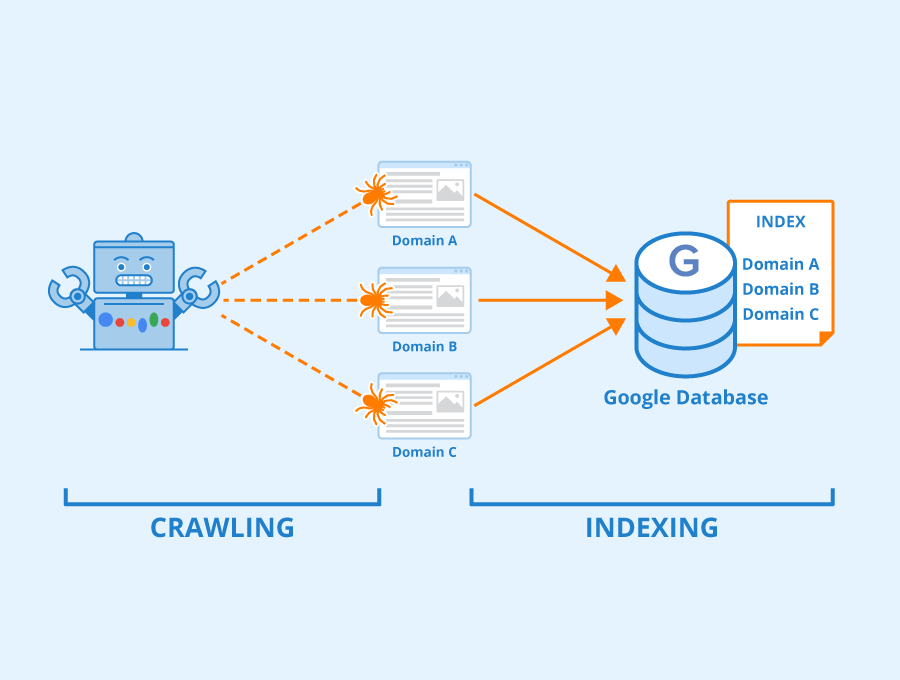
Image source: Seobility – License: CC BY-SA 4.0
We’ll look closer at how this process works in the next section. For now, it can help to think of indexing as an online filing system for website posts and pages, videos, images, and other content. When it comes to Google, this system is an enormous database known as the Google index.
How Does a Search Engine Index a Site?
Search engines like Google use “crawlers” to explore online content and categorize it. These crawlers are software bots that follow links, scan webpages, and gain as much data about a website as possible. Then, they deliver the information to the search engine’s servers to be indexed:
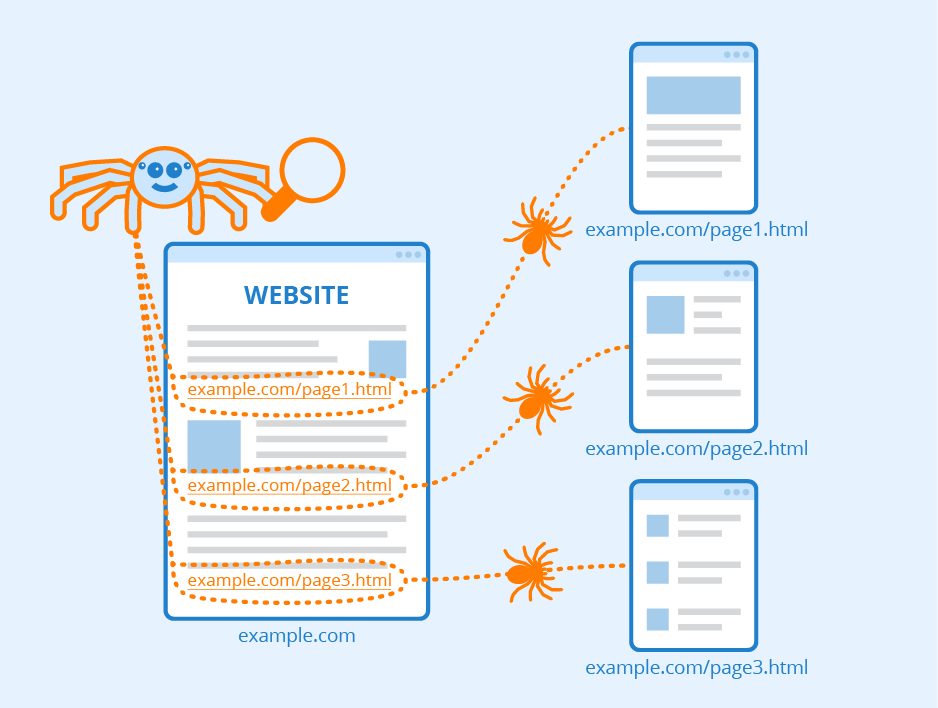
Image source: Seobility – License: CC BY-SA 4.0
Every time content is published or updated, search engines crawl and index it to add its information to their databases. This process can happen automatically, but you can speed it up by submitting sitemaps to search engines. These documents outline your website’s infrastructure, including links, to help search engines crawl and understand your content more effectively.
Search engine crawlers operate on a “crawl budget.” This budget limits how many pages the bots will crawl and index on your website within a set period. (They do come back, however.)
Crawlers compile information on essential data such as keywords, publish dates, images, and video files. Search engines also analyze the relationship between different pages and websites by following and indexing internal links and external URLs.
Note that search engine crawlers won’t follow all of the URLs on a website. They will automatically crawl dofollow links, ignoring their nofollow equivalents. Therefore, you’ll want to focus on dofollow links in your link-building efforts. These are URLs from external sites that point to your content.
If external links come from high-quality sources, they’ll pass along their “link juice” when crawlers follow them from another site to yours. As such, these URLs can boost your rankings in the SERPs:
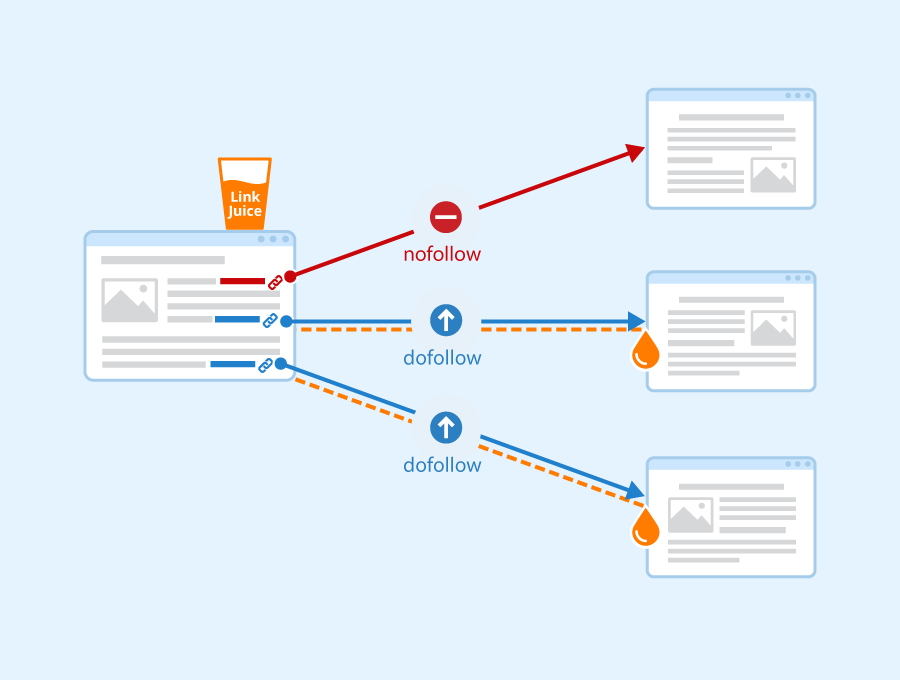
Image source: Seobility – License: CC BY-SA 4.0
Furthermore, keep in mind that some content isn’t crawlable by search engines. If your pages are hidden behind login forms, passwords, or you have text embedded in your images, search engines won’t be able to access and index that content. (You can use alt text to have these images appear in searches on their own, however.)
4 Tools for Search Engine Indexing
You can use several tools to guide how Google and other search engines crawl and index your content. Let’s look at a few of the most helpful options!
1. Sitemaps
Keep in mind that there are two kinds of sitemaps: XML and HTML. It can be easy to confuse these two concepts since they’re both types of sitemaps that end in -ML, but they serve different purposes.
HTML sitemaps are user-friendly files that list all the content on your website. For example, you’ll typically find one of these sitemaps in a site’s footer. Scroll all the way down on Apple.com, and you will find this, an HTML sitemap:
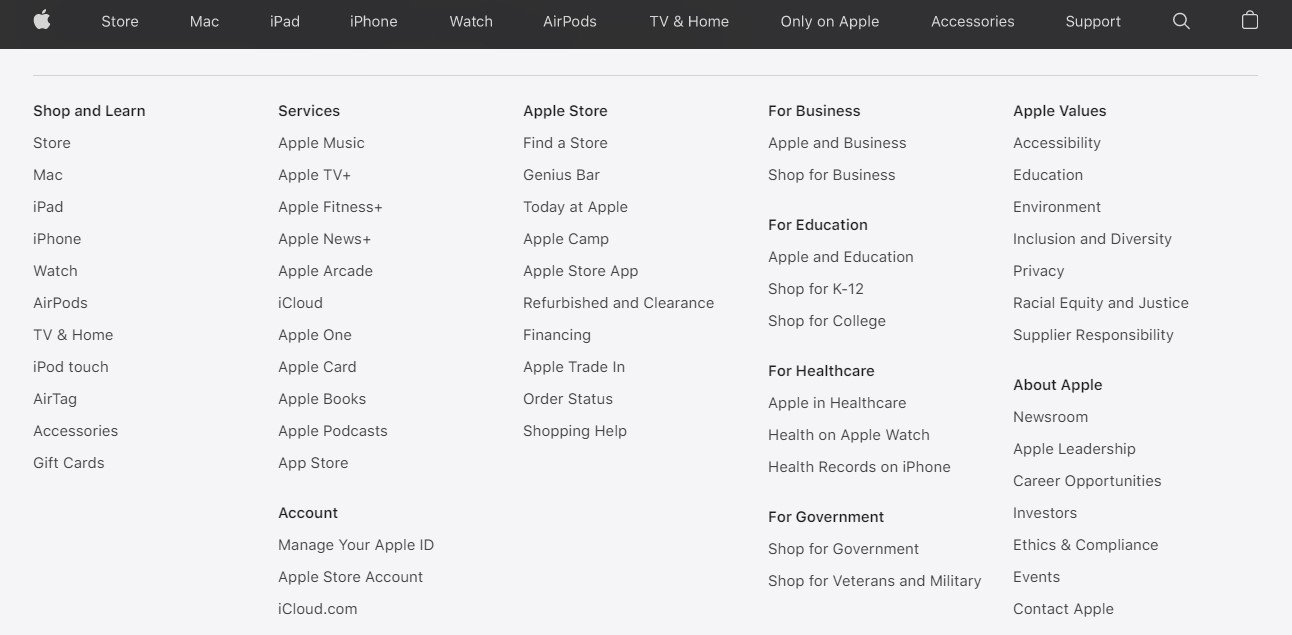
This sitemap enables visitors to navigate your website easily. It acts as a general directory, and it can positively influence your SEO and provide a solid user-experience (UX).
In contrast, an XML sitemap contains a list of all the essential pages on your website. You submit this document to search engines so they can crawl and index your content more effectively:

Keep in mind that we’ll be referring to XML documents when we talk about sitemaps in this article. We also recommend checking out our guide to creating an XML sitemap, so you have the document ready for different search engines.
2. Google Search Console
If you’d like to focus your SEO efforts on Google, the Google Search Console is an essential tool to master:
In the console, you can access an Index Coverage report, which tells you which pages have been indexed by Google and highlights any issues during the process. Here you can analyze problem URLs and troubleshoot them to make them “indexable”.
Additionally, you can submit your XML sitemap to Google Search Console. This document acts as a “roadmap,” and helps Google index your content more effectively. On top of that, you can ask Google to recrawl certain URLs and parts of your site so that updated topics are always available to your audience without waiting on Google’s crawlers to make their way back to your site.
3. Alternative Search Engine Consoles
Although Google is the most popular search engine, it isn’t the only option. Limiting yourself to Google can close off your site to traffic from alternative sources such as Bing:
We recommend checking out our guides on submitting XML sitemaps to Bing Webmaster Tools and Yandex Webmaster Tools. Unfortunately, other search engines, including Yahoo and DuckDuckGo, don’t enable you to submit sitemaps.
Keep in mind that each of these consoles offers unique tools for monitoring your site’s indexing and rankings in the SERPs. Therefore, we recommend trying them out if you want to expand your SEO strategy.
4. Robots.txt
We’ve already covered how you can use a sitemap to tell search engines to index specific pages on your website. Additionally, you can exclude certain content by using a robots.txt file.
A robots.txt file includes indexation information about your site. It’s stored within your root directory and has two lines: a user-agent line that specifies a search engine crawler, and a disallow directive that blocks particular files.
For example, a robots.txt file might look something like this:
User-agent: * Disallow: /example_page/ Disallow: /example_page_2/
In this example, the * covers all search engine crawlers. Then, the disallow lines specify particular files or URL paths.
You simply need to create a simple text file and name it robots.txt. Then, add your disallow data and upload the file to your root directory with a File Transfer Protocol (FTP) client.
FAQs
So far, we’ve covered the basics of search engine indexing. If you still have questions about this SEO concept, we’ll answer them here! (And if you still have one, let us know in the comments so we can answer it there!)
How Can I Get Indexed Better by Search Engines?
You can get indexed better by search engines by creating sitemaps, auditing them for crawling errors, and submitting them to multiple search engines. Additionally, you should consider optimizing your content for mobile devices and reducing your loading times to speed up crawling and indexing.
Frequently updating your content can also alert search engines to crawl and index your “new” pages. Finally, we recommend preventing search engines from crawling duplicate content by using a robots.txt file or deleting it.
Do I Have to Request Search Engines to Crawl My Site?
Search engines will crawl new publicly-available content on the internet, but this process can take weeks or months. Therefore, you might prefer to speed things up by submitting a sitemap to the search engines of your choice.
Do I Have to Alert Search Engines if I Publish New Content?
We recommend updating your sitemap when you publish new content. This approach ensures that your posts will be crawled and indexed more quickly. We recommend using a plugin such as Yoast SEO to generate sitemaps easily.
Is My Content Ever Removed From Google or Other Search Engines?
Google might remove a post or page from its index if the content violates its terms of service. This means the content breaks privacy, defamation, copyright, or other laws in many cases. Google also removes personal data from its index, such as identifiable financial or medical information. Finally, Google may penalize pages that use black hat SEO techniques.
How Can I Get My Content Re-Indexed if It’s Been Removed?
You can ask Google to re-index your content by modifying it to meet the search engine’s Webmaster quality guidelines. Then, you can submit a reconsideration request and wait to see Google’s response.
How Can I Prevent Search Engines From Indexing Certain Pages?
You can prevent search engines from indexing certain pages by adding a noindex metatag to the page’s section. Alternatively, if your content is a media file, you can add it to a robots.txt file. Finally, Google Webmaster Tools enables you to hide a page using the Remove URLs tool.
Conclusion
SEO is a broad field that covers everything from search engine algorithms to off-page optimization techniques. If you’re new to the topic, you might be feeling overwhelmed by all the information. Fortunately, indexing is one of the easier concepts to grasp.
Search engine indexing is an essential process that organizes your website’s content into a central database. Search engine crawlers analyze your site’s content and architecture to categorize it. Then they can rank your pages in their results pages for specific search terms.
Do you have any other questions about search engine indexing? Let us know in the comments section below!
Featured image via Sammby / shutterstock.com
The post The Basics of How Search Engine Indexing Works appeared first on Elegant Themes Blog.